Verilog in a NutShell
Verilog in a NutShell
This is a detour to better understand the GenerateRTL phase of LegUp HLS
语言基础
电路结构的三种描述方法
- 数据流描述: 采用assign 语句,该语句被称为连续赋值语句。
- 行为描述:使用always 或initial 语句块,其中出现的语句被称为过程赋值语句。
- 结构化描述:实例化已有的功能模块。
词法
模块与端口
`timescale 1ns/1ps
module SIMDadd(
input [15:0] A,
input [15:0] B,
input H,
input O,
input Q,
input sub,
output [15:0] Cout
);
//声明语句
/* reg,wire, parameter,
input,output,inout,
function, task ... */
wire [15:0] B_real = sub?(~B):B;
wire [4:0] C0 = A[3:0] + B_real[3:0] + sub;
wire [4:0] C1 = A[7:4] + B_real[7:4] + (C0[4]&(O|H)) + (Q&sub);
wire [4:0] C2 = A[11:8] + B_real[11:8] + (C1[4]&H) + ((Q|O)&sub);
wire [4:0] C3 = A[15:12] + B_real[15:12] + (C2[4]&(O|H)) + (Q&sub);
//语句
assign Cout = {C3[3:0],C2[3:0],C1[3:0],C0[3:0]};
/* initial 语句
always 语句
module 实例化
assign 连续赋值 */
endmodule编译指令
Verilog使用`来表示编译指令编译器一旦遇到某个编译指令,则该指令将在整个编译过程中有效,直到编译器遇到另一个相同的编译指令为止。
- `timescale 1ns/100ps 其中1ns 表 示延时单位. 100ps 表示时间精度,也就是编译器所能接收的最小仿真时间粒度。
- `define用于定义宏例如可以首先定义一个总线宽度的宏为16 ,然后利用这个宏定义 一个宽度为16 的reg 类型数据Data。在一个文件中出现的、define 可以被多个文件使用,也就是说 define 是一种全局性定
义,这是define 与parameter 定义的最大区别。
`define BUS_WIDTH 16
...
reg [`BUS_WIDTH-1: 0] Data;- `ifdef用于条件编译,如下所示,如果先前已经定义了NARROW宏,则参数为16,否则为32
`ifdef NARROW
parameter BUS WIDTH 16;
`else
parameter BUS W 工DTH 32;
`endif- `include 用于嵌入某个文件的内容
驱动与赋值
- 线网是被驱动的,该值不被存储,在任意一个仿真步进上都需要重新计算。
- 寄存器是被赋值的,且该值将在仿真过程中被保存,直到再次对该变量进行赋值。
reg A_xor_wire;
assign #1 A xor wire eqO^eq1;
always @ (eqO or eq1)
A_xor_wire = #1 eqO^eq1;第一种描述方式使用assign语句, Verilog 中将其称为连续赋值语句( Continously Assignment) ,实际就是连续驱动的过程,也就是说在任意一个仿真时刻,当前时刻eq0 和eq1相异或的结果决定了1ns 以后(语句#1 的延时控制)线网变量A_xor_wire 的值,不 管eq0 和eq1 变化与否,这个驱动过程一直在在,因此称为连续驱动。要知道,在仿真器中,线网变量是不占用仿真内存空间的。
第二种描述方式使用了”always” 语句,后面紧跟一个敏感列表@ (eq0 or eq1) ,该语句 只有在eq0 或eq1 发生变化后才会执行,在eq0和eq1没有发生变化时,A_xor_wire需要保持原来的值不变。因此从仿真语义上讲,需要一个存储单元,也可以说是寄存器,来保存 A_xor_wire 变量的中间值,这就是Verilog 语言中寄存器类型变量的来历,而这个 A_xor_wire 变量需要被定义为reg 类型。注意这里A_xor_wire虽然并定义成了reg类型,但是在综合后该描述被综合成了纯组合电路。
并发与顺序
在Verilog 语言的module 中,所有描述语句(包括连续赋值语句、行为语句块always 和initial 以及模块实例化等)都是并行发生的。 在语句块always 和initial 语句块内部可以存在两种语句组。
begin ... end;: 顺序语句组fork ... join;: 并行语句组
描述方式与设计层次
数据流描述
在数字电路中,信号经过组合逻辑时会类似于数据流动,即信号从输入流向输出,并不 会在其中存储。当输入发生变化时,总会在一定时间以后体现在输出端。同样,我们可以模 拟数字电路的这二特性,对其进行建模,这种建模方式通常被称为数据流建模。数据流描述 中最基本的语句是assign 连续赋值语句。多用来对组合电路进行建模。
连续驱动: 只要输入变化,就会导致该语句的重新计算
只有线网类型的变量才可在assign语句中被赋值:连续赋值语句中被赋值的变量在仿真器中不会存储其值,因此该变量是线网类型(Net) 的,而不是寄存器类塑的。 另外,线网类型的变量可以被多重驱动,也就是说可以在多个连续赋值语句中驱动同一个线网。
并行性:多个assign语句之间时并行执行的
多驱动线网
可以使用wor 线网类型将不同的输出”线或”在一起。同样,可以使用wand 线网类型将不同的输出”线与”在一起。如果要实现多个三态总线相连,可以采用tri型线网。
module WO(A, B, C, D, WireOr, WireTri, En1_n, En2_n);
input A, B, C, D;
output WireOr;
wor WireOr; //显式定义为wor 类型
assign WireOr = A ^ B;
assign WireOr = C & D;
output WireTri;
tri WireTri; //显式定义为tri 类型
assign WireTri = (En1_n)?1'bZ (A^B);
assign WireTri = (En2_n)?1'bZ (C&D);
endmodule行为描述
在initial 和always 的后面-般要跟语句或语句组( statement group) 。 语句可以是非阻塞过程赋值、阻塞过程赋值、连续过程赋值或高级编辑语句。initial 语句在0 仿真时间执行,丽且只执行一次always 语句同样在0仿真时间开始执行,但是它将一直循环执行。
过程赋值语句
所谓过程赋值语句就是在initial 和always 语句块中的赋值语句。赋值对象只能是寄存器变量。右边的表达式可以是任意操作符的表达式。
阻塞赋值
寄存器变量 = 表达式;- 右边表达式的计算和对左边寄在器变量的赋值是一个统一的原子操作中的两个动作,这两个动作之间不能再插入其他任何动作。
- 如果有多个阻塞赋值语句顺序出现在begin…end 语句中,则前面的语句在执行时将完全阻塞后面的语句,直到前面语旬的赋值完成以后,才会执行下一句中右边表达式的 计算。
非阻塞赋值
寄存器变量 <= 表达式;在执行该语句时,首先计算右边的表达式,而且并不立刻为左边的变量赋值。如果有多个非阻塞赋值语句顺序出现在begín…end 语句中,那么前面语句的执行并不会阻塞后面语句的执行。
语句组
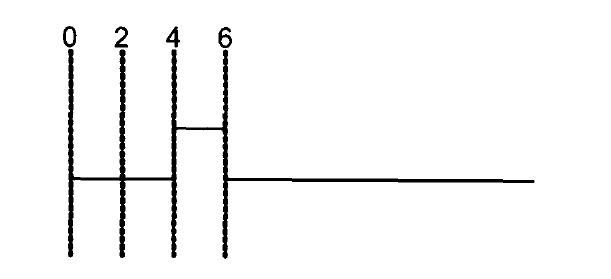
主要了解以下fork ... join: 语句组中语句是并行执行的
initial
fork
DataBin 0;
# 6 DataBin 0;
# 4 DataBin 1;
# 2 DataBin 0;
join将产生如下的波形
编程语句
if-else 语句
if 语句后面跟语句或语句组(begin…end 或fork…join) ,常和else 搭配来实现不同条件下的各种情况。if 也可以单独使用。
- 在if-else 语句中,条件是从上到下逐条检查的。因此当满足一个条件时,就会执行其后的语句,跳过else 后面的语句。当所有条件都不满足时,便执行最后-条else 后面的语句。可以说if-else 语句是有优先级顺序的。
- 在使用if…else 语句时,尤其是当该语句被用在组合逻辑中时,需要注意不要引入Latch 电路
always @(sel or a or b or c)
begin
if (sel == 2'b00)
q = a;
else if (sel == 2'b01)
q = b;
else if (sel == 2'b10)
q = c;
end最后一个条件sel==2'b11的语句没有被写出,言下之意是,当sel 为2’b11 时, q 值需要保持不变。这个代码在综合时会产生锁存器。
case语句
与if-else 语句不同的是,在case 语句中,所有被判断的分支条件都具有一样的优先级。
与if-else 语句类似的是,case 语句同样需要考虑所有可能的情况,否则将会产生出不想要的锁存器。
case语句有两个派生语句
casez, casex,casez 语句将分支条件中所有的z 都看作”不关心”的值,而不看作任何逻辑值。条件中的z 可以改写为?,casex 语句将分支条件中所有的x 和z 都看作”不关心”的值,而不看作任何逻辑值。
casex (encoder)
4'b1xxx : high_val = 3;
4'b01xx : high_val = 2;
4'b001x : high_val = 1;
4'b0001 : high_val = 0;
default : high_val = 0;
endcase这里通过casex语句生成了一个优先级译码器。
循环语句
forever #25 clk = ~clk; // 永远重复循环体
repeat (8) begin ... end // 重复循环体八次
while (条件) begin ... end
for (i=0; i< 7; i++) begin ... end结构化描述
结构化描述就是说在设计中实例化己有的功能模块,这些功能模块包括门原语、用户自定义原语(UDP) 和其他模块(module)。
module Ha1fAdd (X , Y, SUM, C out); //半加器模块
HalfAdd u_HalfAdd_B( //半加器实例B
.X (C in),
.Y (HalfAdd A SUM),
.SUM (SUM),
.C_out (HalfAdd_B_COUT));
参数化模块
module 中的参数一般是用作定义其中常量的工具。在Verilog 语言中,当实例化模块时,用户可以修改模块中的参数,用来实现不同的特性。这个定制过程是通过”新参数直接代入”或”参数重定义”来完成的。
module mymodule (...);
parameter a = 2;
parameter b = 3;
...
endmodule参数定制方法
- 通过
defparam关键字重新定义模块中的参数, 使用defparam的方法重新定义参数时,可以根据需要重新定义部分参数,而其他参数将保留缺省值。
module xxx (...);
...
mymodule M1 (...); //实例化mymodule
defparam
M1.a = 3; //重新定义M1中的参数a和b
M1.b = 4;
...
endmodule- 直接在实例化模块时带入参数,使用这种参数直接代入法时需要注意一点,即所有的参数都要按顺序列出来,不能遗漏,也不能颠倒顺序,否则就会对应不上。
module xxx (...);
...
mymodule #(
3, // 重新定义M1中的参数a和b
4) M1 (...); //实例化mymodule
...
endmoduleRTL级建模
所谓寄存器传输级(RTL 级)就是在描述电路的时候,只需要关注寄存器本身,以及寄存器到寄存器之间的逻辑功能,而不用关心寄存器和组合逻辑的实现细节(具体用了多少逻辑门等)。典型的RTL设计分为三个部分:
- 时钟域描述: 描述设计中使用的所有时钟、时钟之间的主从与派生关系以及时钟域之间的转换。
- 时序逻辑描述(寄存器描述): 根据时钟沿的变换,描述寄存器之间的数据传输方式。
- 组合逻辑描述: 描述电平敏感信号的逻辑组合方式和逻辑功能。
常用建模方式
赋值
对于时序逻辑,即always 模块的敏感表为边沿敏感信号(多为时钟或复位的正沿或负沿),统一使用非阻塞赋值”<=”。
对于always 模块的敏感表为电平敏感信号的组合逻辑,统一使用阻塞赋值”=”。
对于assign 关键宇描述的组合逻辑(通常称之为连续赋值语句) ,统一使用”=” 变量被定义为wire型信号。
reg [3:0] cnt_out;
a1ways@(posedge c1ock)
cnt_out <= cnt_out + 1;
a1ways@(cnt_out)
cnt_out_p1us = cnt_out + 1; 寄存器电路的建模
- 寄存器信号声明: 寄存器被定义为reg 型,只有当信号被定义为reg 型,且处理该信号的always 敏感表为
posedge或negedge沿敏感时,该信号才会被实现为寄存器。 - 时钟输入: 在每个时钟的正沿或负沿对数据进行处理.时钟的正沿有效还是负沿有效,是由always 敏感表中的
posedge或negedge决定的。 - 异步复位/置位: 绝大多数目标器件的寄存器模型都包含异步复位/置位端.所谓异步复位/置位,是指无论时钟沿是否有效,当复位/置位信号的有效沿到达时,复位/置位会立即发挥功能.指定异步复位/置位时,只需在always 的敏感表中加入复位/置位信号的有效沿即可.下面描述的异步复位电路是最常用的寄存器复位形式之一。
reg [3:0] cnt_reg;
always @ (posedge clock or negedge reset )
if (! reset )
cnt reg <= 4'bOOOO;
else begin ... end- 同步复位/置位: 任何寄存器都可以实现同步复位/置位功能.指定同步复位/置位时always 的敏感表中仅有时钟沿信号,当同步复位/置位信号发生变化时,同步复位/置位并不立即发生,仅当时钟沿采到同步复位/置位的有效电平时,才会在时钟沿到达时刻进行复位/置位操作。
reg [3:0] cnt_reg;
always @ (posedge clock)
if (! reset )
cnt reg <= 4'bOOOO;
else begin ... end- 同时使用时钟上升沿和下降沿的问题: 有时因为数据采样或调整数据相位等需求,设计者会在一个always 的敏感表中同时使用时钟的posedge 和negedge ,或者在两个always 的敏感表中分别使用时钟的posedge 和negedge ,对某些寄存器电路进行操作(在这两种描述下,当时钟上升沿或时钟下降沿到达时,该寄存器电路都会做相应的操作. 这个双沿电路往往可以等同于使用了原时钟的倍频时钟的单沿操作电路).对于PLD 设计而言,不推荐同时使用时钟的上升沿、下降沿,因为PLD 内嵌的PLL/DLL 和一些时钟电路往往只能对时钟的一个沿保证非常好的指标,而另一个沿的抖动、偏斜、斜率等指标不见得非常优化,有时同时使用时钟的正、负沿会因时钟的抖动、偏斜、占空比、斜率等问题而造成一定的性能恶化。因此推荐的做法是,将原时钟通过PLL/DLL 倍频,然后使用倍频时钟的单沿(如上升沿)进行操作。
组合逻辑建模
always 模块的敏感表为电平敏感信号的组合逻辑电路: 这种形式的组合逻辑电路应用非常广泛,如果不考虑代码的复杂性,几乎任何组合逻辑电路都可以用这种方式建模。always 模块的敏感表为所有判定条件和输入信号,请读者在使用这种结构描述组合逻辑时,一定要将敏感表写完整。在always模块中可以使用if.. .else… 、case 、for 循环等各种RTL 关键宇结构。在always 模块中推荐使用阻塞赋值”=”虽然信号被定义为reg 型,但是最终综合实现的结果并不是寄存器,而是组合逻辑,将信号定义为reg 型只是为了满足语法要求而已。
assign 等语句描述的组合逻辑电路: 这种形式的组合逻辑电路适用于描述那些相对简单的组合逻辑,信号一般被定义为wire 型,常用的assign 结构除了直接赋值逻辑表达式外,还可以使用?语句。
双向端口与三态信号建模
- 仅在顶层定义双向总线和实例化的三态信号,禁止在除顶层以外的其他层次赋值高阻态”z” ,在顶层将双向信号分为输入信号和输出信号两种类型,然后根据需要分别传递到不同的子模块中。这样做的另一个好处在于便于描述仿真激励。
inout [7:0] data_bus;
wire [7:0] data_in, data_out;
assign data_in = data_bus; //输入输出分离
assign data_bus = (sel)? data_out : 8'bZ; //三态输出Mux建模
- 简单的Mux 用?表达式建模,信号被定义为wire 型,使用?表达式的判断条件描述Mux 选择端的逻辑关系。
wire mux_out;
assign mux_out = (en)? a:b;- 复杂的Mux 用case 或嵌套的if.. .else 建模,信号被定义为reg 型,
case或if.. .else的每个条件分支均分别对应Mux 的某路选择输出。
reg mux_out;
always @ (en or a or b or C or d)
case(en)
2'b00: mux_out = a;
2'b01: mux_out = b;
2'b10: mux_out = c;
2'b11: mux_out = d;
endcase存储器建模
wire [7:0] b; //定义了一个八位的wire型数据
wire [8:1] b; //和上面的一样 [n-1:0]和[n:1]都可以[n-1:0]和[n:1]代表该数据的位宽,即该数据有几位。最后跟着的是数据的名字。如果一次定义多个数据,数据名之间用逗号隔开。
wire [0:7] a;
wire [7:0] b;
b[0:2] //非法,低位在左面了
a[0:2] //向量a的最高两位
assign a[0:3] = b[3:0] // a[0] = b[3], a[1] = b[2], a[2] = b[1], a[3] = b[0]向量通过[high:low]或者[low:high]进行说明,【方括号左边的数总是代表向量的最高有效位,并且在读取时,高位总应该写在范围说明符的左面】
reg [255:0] data1;
reg [0:255] data2;
reg [7:0] byte;
byte = data1[31-: 8]; //从第31位开始,宽度为8位,相当于data1[31:24]
byte = data2[24+: 8]; //从第24位开始,宽度为8位,相当于data1[24:31][<starting_bit>+: width]: 从起始位开始递增,位宽为width
[<starting_bit>-: width]: 从起始位开始递减,位宽为width
reg y1 [11:0]; // y is an scalar reg array of depth=12, each 1-bit wide
wire [0:7] y2 [3:0] // y is an 8-bit vector net with a depth of 4
reg [7:0] y3 [0:1][0:3]; // y is a 2D array rows=2,cols=4 each 8-bit wide不要将数组和向量混淆,向量为一个单独的原件,它的位宽为n, 数组由多个原件组成,其中每个原件的位宽为n或1。
reg [msb:lsb] MemoryName [memsize-1:0];
// example, 数据位宽为8bit, 64个
reg [7:0] RAM8x64 [0:63];
[error: ] RAM8x64 [32][2];
[error: ] RAM8x64 [32][6:7];使用存储单元时,不能直接引用存储器某地址的某比特位值,如想对地址为”32 “的第2bit 和高2bit 的值进行操作,则上面这两种描述都是错误的。正确的操作方法是,先将存储单元赋值给某个寄存器,然后在对该寄存器的某位进行相关操作。
串并转换建模
可以选用移位寄存器、RAM 等来实现。对于数据量比较小的设计来说,可以使用移位寄存器完成串并转换:对于排列顺序有规定的串并转换,可以用case 语句判断实现:对于复杂的串并转换,还可以用状态机实现。
reg [7: 0] pal_out;
always @ (posedge clk or negedge rst)
if ('rst)
pal_out <= 8'bO;
else
pal_out <= {pal_out, srl_in};同步与异步复位
一般来说,逻辑电路的任何一个寄存器、存储器结构和其他逻辑单元都必须要附加复位逻辑电路,以保证电路能够从错误状态中恢复,可靠地工作。常用的复位信号为低电平有效信号,在应用时外部引脚接上拉电阻,这样能增加复位电路的抗干扰性能。
同步复位电路建模
指定同步复位时, always 的敏感表中仅有时钟沿信号,仅仅当时钟沿采到同步复位的有效电平时,才会在时钟沿到达时刻进行复位操作。如果目标器件或可用库中的触发器本身包含同步复位端口,则在实现同步复位电路时可以直接调用同步复位端。然而很多目标器件(如PLD) 和ASIC 库的触发器本身并不包含同步复位端口,这样复位信号与输入信号组成某种组合逻辑(比如复位低电平有效,只需复位与输入信号两者相与即可) ,然后将其输入到寄存器的输入端。为了提高复位电路的优先级,一般在电路描述时使用带有优先级的if…else 结构,复位电路在第一个if 下描述,其他电路在else 或else…if 分支中描述。
always @ (posedge clk)
if (!rst) begin ... end
else begin ... end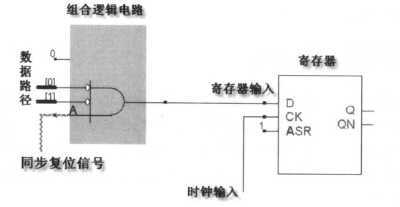
优点
- 使用同步复位可以设计100% 的同步时序电路,有利于时序分析,其综合结果的频率往往较高
- 同步复位仅在时钟的有效沿生效,可以有效地避免因复位电路毛刺造成的亚稳态和错误.同步复位在进行复位和释放复位信号时,都是仅当时钟沿采到复位信号电平变化时才进行相关操作,如果复位信号树的组合逻辑出现了某种毛刺,此时时钟沿采样到毛刺的概率非常低,这样通过时钟沿采样,可以十分有效地过滤复位电路组合逻辑产生的毛刺,增强了电路稳定性.
缺点
- 很多目标器件(FPGA) 和ASIC 库的触发器本身并不包含同步复位端口,使用同步复位会增加更多逻辑资源
- 同步复位的最大问题在于必须保证复位信号的有效时间足够长,这样才能保证所有触发器都能有效地复位。设计中还要考虑到同步复位信号树通过所有相关组合逻辑路径时的延时,以及由于时钟布线产生的skew。这样,只有同步复位大于时钟最大周期,加上同步信号穿过的组合逻辑路径延时,再加上时钟偏斜时,才能保证同步复位可靠、彻底。
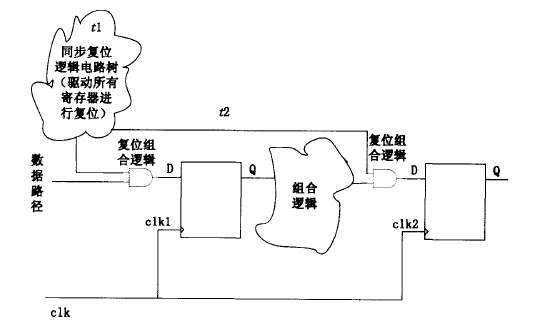
Tsyn_rst > Period_max + (clk2 - clk1) + t1 + t2;异步复位电路建模
指定异步复位时,只需在always 的敏感表中加入复位信号的有效沿即可,当复位信号有效沿到达时,无论时钟沿是否有效,复位都会立即发挥其功能。
always @ (posedge clk or negedge rst)
if (!rst) begin ... end
else begin ... end- 大多数目标器件(如FPGA 和CPLD) 和ASIC 库的触发器都包含异步复位端口,异步复位会被直接接到触发器的异步复位端口。
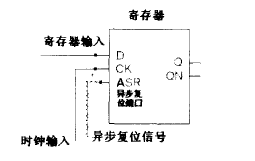
优点
- 对于大多数FPGA ,都有专用的全局异步复位/置位资源(GSR, Global SetReset ),使用GSR 资源,异步复位到达所有寄存器的偏斜(skew) 最小。
- 异步复位设计简单,节约资源。
缺点
- 异步复位的作用和释放与时钟沿没有直接关系,异步复位生效时问题并不明显;但是当释放异步复位时,如果异步复位信号释放时间和时钟的有效沿到达时间几乎一致,则容易造成触发器输出为亚稳态,形成逻辑错误。
- 如果异步复位逻辑树的组合逻辑产生了毛刺,则毛刺的有效沿会使触发器误复位,造成逻辑错误。
推荐的复位方式
推荐的复位电路设计方式是异步复位、同步释放。这种方式,可以有效地继承异步复位设计简单的优势,并克服异步复位的上述风险与缺陷。异步复位,同步释放的设计方法有很多,关键是如何保证同步地释放复位信号。
reg reset_reg;
always @ (posedge clk)
reset_reg <= rst;
always @ (posedge clk or negedge reset reg)
if (!reset_reg) begin ... end
else begin ... end
//本例使用时钟将外部输入的异步复位信号寄存一个节拍后,再送到触发器异步复位端口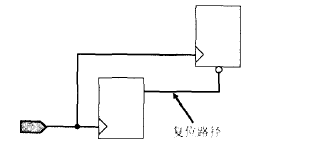
常用设计技巧
同步设计与多时钟处理
亚稳态
异步时钟域数据转换的核心就是要保证下一级时钟对上级数据来样的Setup 时间和Hold时间。如果触发器的Setup 时间或者Hold 时间不能得到满足,则有可能会产生亚稳态,此时触发器输出端Q 在有效时钟沿到达之后比较长的一段时间内将处于不确定的状态。在这段时间内Q 端将会产生毛刺并不断振荡,最终固定在某一电压值上,此电压值并不一定等于原来数据输入端D 的数值,这段时间称为决断时间(Resolutíon tíme) 。经过决断时间之后, Q 端将稳定到0或1,但是究竟是0还是1这是随机的,与输入没有必然的关系。
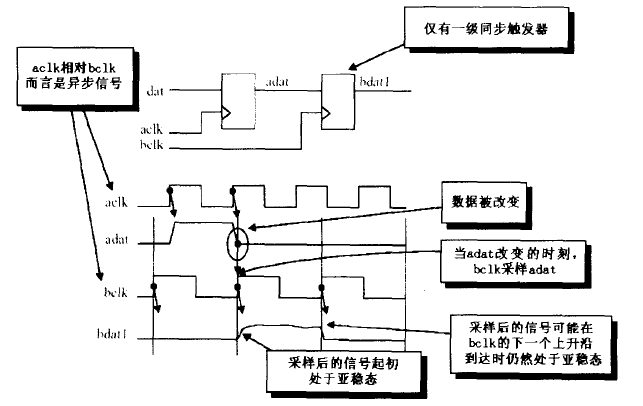
- 使用两级以上寄存器采样可以有效地降低亚稳态继续传播的概率。其原理是即使第一个触发器的输出端存在亚稳态,但经过→个Clk 周期后,第二个触发器D 端的电平仍未稳定的概率会非常小,因此第二个触发器Q 端基本不会产生亚稳态。如果再添加一级寄存器,使同步采样达到3 级,则末级输出为亚稳态的概率几乎为0 。
- 使用如图 所示的两级寄存器采样仅能降低亚稳态的概率,但是并不能保证第三级输出的稳态电平就是正确电平。前面说过,经过决断时间之后,寄存器输出的电平是一个不确定的稳态值,也就是说这种处理方法并不能排除采样错误的产生,这时就要求所设计的系统对采样错误要有一定的容忍度。
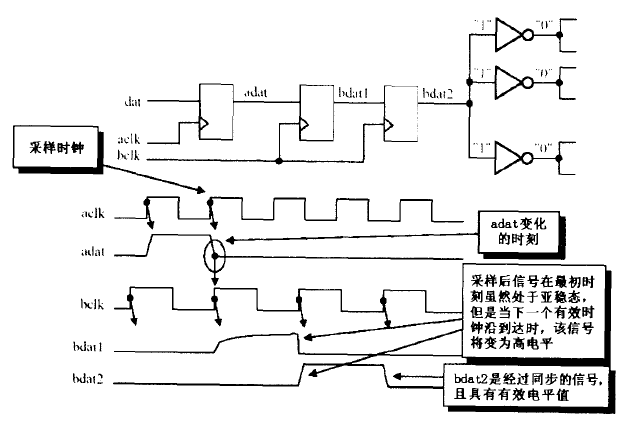
异步时钟域同步
两个域的时钟频率相同,但是相位差不固定,或者相位差固定,但是不可测,简称为同频异相问题
两个时钟域频率不同,简称为异频问题
同频异相
同频异相问题的简单解决方法是用后级时钟对前级数据采样两次,即通常所述的用寄存器打两次这种做法可以有效地减少亚稳态的传播,使后级电路数据都是有效电平值。但是这种做法并不能保证两级寄存器采样后的数据是正确的电平值,因为一旦Setup 或Hold 时间不满足,采样发生亚稳态,则经决断时间后,还是可能判决到错误的电值
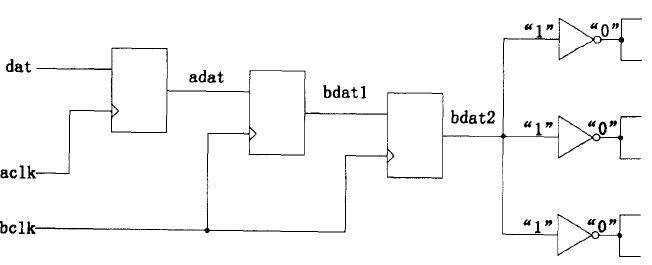
异频问题
解决异频问题的可靠方法就是使用DPRAM 或FIFO。用上级随路时钟写入上级数据,然后用本级时钟读出数据。但是由于时钟频率不同,所以两个端口的数据吞吐率不一致,设计时一定要开好缓冲区,并通过监控( Full 、Half、Empty 等指示)确保数据流不会溢出。
模块划分原则
- 对每个同步时序设计的子模块的输出使用寄存器(Registering) 。
- 将相关的逻辑或者可以复用的逻辑划分在同一模块内。
- 将不同优化目标的逻辑分开。
- 将时序约束较松的逻辑归入同一模块。
- 将存储逻辑独立划分成模块。
- 合适的模块规模。
组合逻辑设计注意事项
always 组合逻辅信号敏感表
- 正确的信号敏感表设计方法是将always 模块中使用到的所有输入信号和条件判断信号都列在信号敏感表中。
- 希望通过信号敏感表的增减完成某项逻辑功能是大错特错的。
- 不完整的信号敏感表有时会造成综合前的仿真结果与综合后仿真、布局布线后仿真的结果不一致。
增减信号敏感表后得到的综合结果其实是完全-致的。之所以在增减信号敏感表后得到不同的仿真结果,是因为仿真器的工作机制所致,大多数仿真器是由数据流和时钟周期驱动的,如果信号敏感表中没有某个信号,则无法触发和该信号相关的仿真进程,从而得到不同的仿真结果。
组合逻辑反馈环路
组合逻辑反馈环路是数字同步逻辑设计的大忌,它最容易因振荡、毛刺、时序违规等问题引起整个系统的不稳定和不可靠。如果Q 输出为0 ,经组合逻辑运算后为异步复位端有效,则电路将会进入不断清零的死循环。
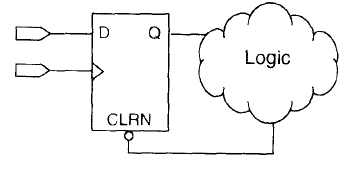
- 牢记任何反馈环路必须包含寄存器。
- 检查综合、实现报告的Warning 信息,发现Combinational Loops 后立即进行相应的修改。
- 组合反馈环的逻辑功能完全依赖于其反馈环路上组合逻辑的门延时和布线延时等,如果这些传播延时有任何改变,则该组合反馈环单元的整体逻辑功能将彻底改变,而且改变后的逻辑功能很难确定。
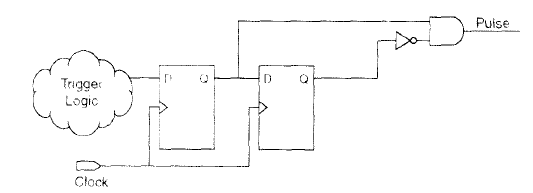
脉冲产生器
常用的同步脉冲产生方法如图所示。该设计的脉冲宽度不因器件改变或设计移植而改变,恒等于时钟周期,避免了异步设计的诸多不确定因素,其时序路径便于计算、STA分析和仿真验证。
逻辑复制
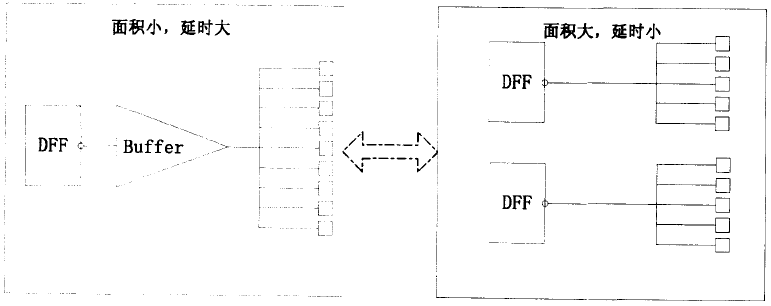
逻辑复制是一种通过增加面积向改善时序条件的优化手段。逻辑复制最常使用的场合是调整信号的扇出。如果某个信号需要驱动后级的很多单元,换句话说,也就是其扇出非常大,那么为了增加这个信号的驱动能力,就必须插入很多级Buffer ,这样就在一定程度上增加了这个信号路径的延时。这时可以复制生成这个信号的逻辑,用多路同频同相的信号驱动后续电路,使平均到每路的扇出变低,这样不需要插入Buffer 就能满足驱动能力增加的要求,从而节约了该信号的路径延时。
香农扩展运算
F(a,b,c) = aF(1,b,c) + bar(a)F(0,b,c)香农扩展相当于逻辑复制,提高频率:向卡诺逻辑化简相当于资源共享,节约面积。香农扩展通过增加MUX 来缩短某个优先级高、但是组合路径长的信号的路径延时,从而提高了该关键路径的工作频率,这里a为关键路径信号,延时最大。
状态机
基本要素及分类
状态机的基本要素有3 个,分别是状态、输出和输入:
- 状态: 也叫状态变量。在逻辑设计中,使用状态划分逻辑顺序和时序规律。比如设计伪随机码发生器时,可以用移位寄存器序列作为状态;在设计电机控制电路时,可以将电机的不同转速作为状态;在设计通信系统时,可以将信令的状态作为状态变量等。
- 输出: 输出指在某一个状态时特定发生的事件。如设计电机控制电路时,如果电机转速过高,则输出为转速过高报警,也可以伴随减速指令或降温措施等。
- 输入: 指状态机中进入每个状态的条件,有的状态机没有输入条件,其中的状态转移较为简单,有的状态机有输入条件,当某个输入条件存在时才能转移到相应的状态。
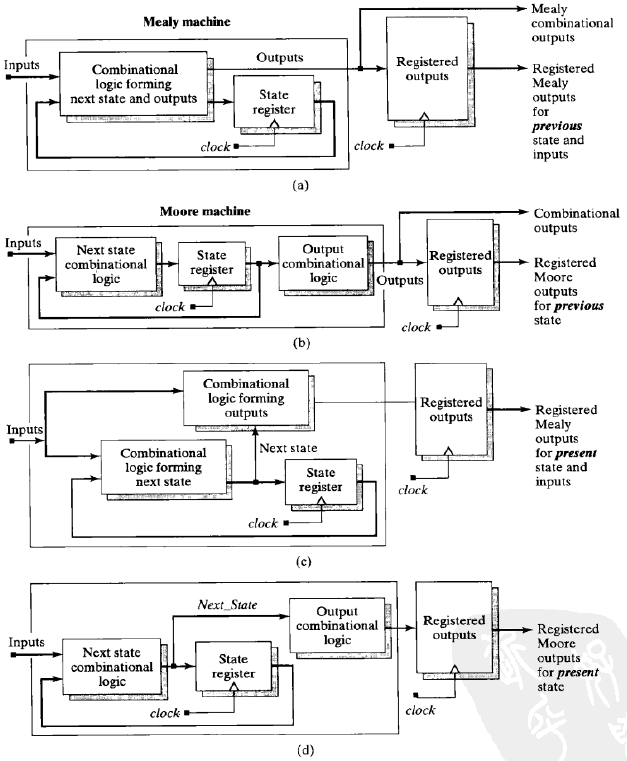
根据状态机的输出是否与输入条件相关,可将状态机分为两大类,即Moore型状态机和Mealy型状态机:
- 摩尔型状态机: 摩尔型状态机的输出仅仅依赖于当前状态,而与输入条件无关。
- 米勒型状态机:米勒型状态机的输出不仅依赖于当前状态,而且取决于该状态的输入条件。
状态机的不同写法
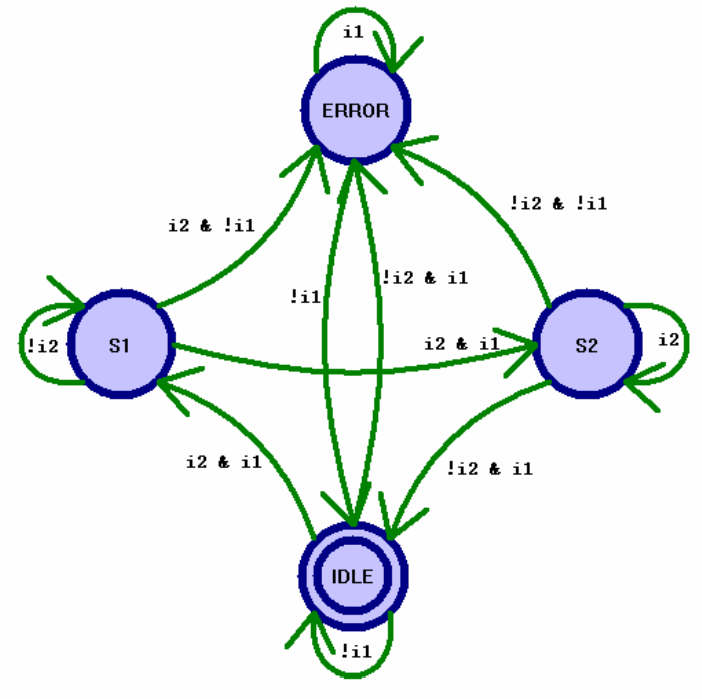
这里我 们选用了一个非常典型的摩尔型状态机,共有 4 个状态:IDEL, S1, S2, ERROR;输入信号 为时钟 clk,低电平异步复位信号 nrst,输入信号 i1,i2,输出信号为 o1,o2 和 err,状态关 系如图 6-2 所示。状态的输出下:
| 状态 | 输出 |
|---|---|
| IDLE | {o1,o2,err} = 3’b000; |
| S1 | {o1,o2,err} = 3’b100; |
| S2 | {o1,o2,err} = 3’b010; |
| ERROR | {o1,o2,err} = 3’b111; |
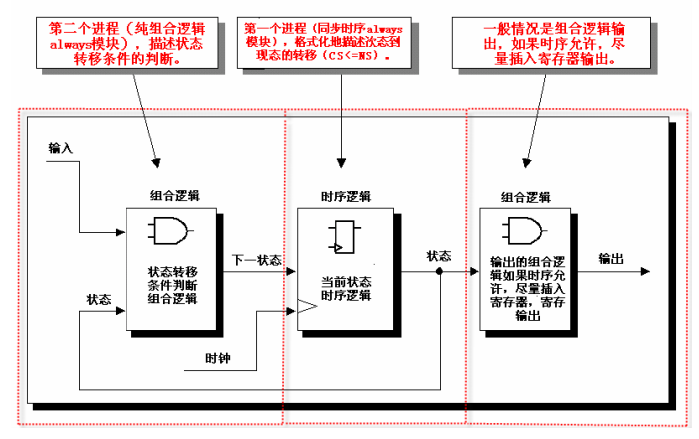
两段式写法
//2-paragraph method to describe FSM
//Describe sequential state transition in 1 sequential always block
//State transition conditions in the other combinational always block
//Package state output by task. Then register the output
module state2 ( nrst,clk,i1,i2,o1,o2,err);
input nrst,clk;
input i1,i2;
output o1,o2,err;
reg o1,o2,err;
reg [2:0] NS,CS;
parameter [2:0] //one hot with zero idle
IDLE = 3'b000,
S1 = 3’b001,
S2 = 3’b010,
ERROR = 3’b100;
//sequential state transition
always @ (posedge clk or negedge nrst)
if (!nrst)
CS <= IDLE;
else
CS <= NS;
//combinational condition judgment
always @ (CS or i1 or i2)
begin
NS = 3'bx;
ERROR_out;
case (CS)
IDLE: begin
IDLE_out;
if (~i1) NS = IDLE;
if (i1 && i2) NS = S1;
if (i1 && ~i2) NS = ERROR;
end
S1: begin
S1_out;
if (~i2) NS = S1;
if (i2 && i1) NS = S2;
if (i2 && (~i1)) NS = ERROR;
end
S2: begin
S2_out;
if (i2) NS = S2;
if (~i2 && i1) NS = IDLE;
if (~i2 && (~i1)) NS = ERROR;
end
ERROR: begin
ERROR_out;
if (i1) NS = ERROR;
if (~i1) NS = IDLE;
end
endcase
end
//output task
task IDLE_out;
{o1,o2,err} = 3'b000;
endtask
task S1_out;
{o1,o2,err} = 3'b100;
endtask
task S2_out;
{o1,o2,err} = 3'b010;
endtask
task ERROR_out;
{o1,o2,err} = 3'b111;
endtask
endmodule两段式 FSM 的核心就是:一个 always 模块采用同步时序描述状态转移;另一个模块采用组合逻辑判断状态转移条件,描述状态转移规律。
一般来说,在这个组合 always 敏感表下先写一个默认的下一状态“NS”的描述,然后 根据实际的状态转移条件由内部的 case 或者 if…else 条件判断确定正确的转移。
推荐在敏感表下的默认状态为不定状态 X,这样描述的好处有两个:第一在仿真时可以 很好的考察所设计的 FSM 的完备性,如果所设计的 FSM 不完备,则会进入任意状态,仿真 很容易发现;第二个好处是综合器对不定态 X 的处理是“Don’t Care”,即任何没有定义的 状态寄存器向量都会被忽略。
对于每个输出,一般用组合逻辑描述,比较简便的方法是用 task/endtask 将输出封装起 来,这样做的好处不仅仅是写法简单,而且利于复用共同的输出。例如本例中 S1 状态的输 出被封装为 S1_out,在组合逻辑 always 模块中直接调用即可。
三段式写法
module state3 ( nrst,clk,i1,i2,o1,o2,err);
input nrst,clk;
input i1,i2;
output o1,o2,err;
reg o1,o2,err;
reg [2:0] NS,CS;
parameter [2:0] //one hot with zero idle
IDLE = 3'b000,
S1 = 3’b001,
S2 = 3’b010,
ERROR = 3’b100;
//sequential state transition
always @ (posedge clk or negedge nrst)
if (!nrst)
CS <= IDLE;
else
CS <= NS;
//combinational condition judgment
always @ (nrst or CS or i1 or i2)
begin
NS = 3'bx;
case (CS)
IDLE: begin
if (~i1) NS = IDLE;
if (i1 && i2) NS = S1;
if (i1 && ~i2) NS = ERROR;
end
S1: begin
if (~i2) NS = S1;
if (i2 && i1) NS = S2;
if (i2 && (~i1)) NS = ERROR;
end
S2: begin
if (i2) NS = S2;
if (~i2 && i1) NS = IDLE;
if (~i2 && (~i1)) NS = ERROR;
end
ERROR: begin
if (i1) NS = ERROR;
if (~i1) NS = IDLE;
end
endcase
end
//3rd always block, the sequential FSM output
always @ (posedge clk or negedge nrst)
if (!nrst)
{o1,o2,err} <= 3'b000;
else begin
{o1,o2,err} <= 3'b000;
case (NS)
IDLE: {o1,o2,err}<=3'b000;
S1: {o1,o2,err}<=3'b100;
S2: {o1,o2,err}<=3'b010;
ERROR: {o1,o2,err}<=3'b111;
endcase
end
endmodule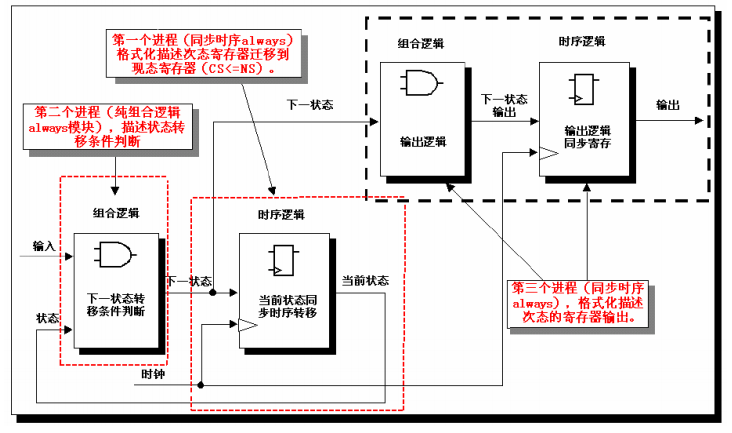
三段式与两段式 FSM 描述的最大区别在于两段式采用了组合逻辑输出,而三段式巧妙地根据下一状态的判断,用同步时序逻 辑寄存 FSM 的输出。另一方面,三段式描述方法与两段式描述相比,虽然代码结构复杂了一些,但是换来的 优势是使 FSM 做到了同步寄存器输出,消除了组合逻辑输出的不稳定与毛刺的隐患,而且 更利于时序路径分组,一般来说在 FPGA/CPLD 等可编程逻辑器件上的综合与布局布线效果 更佳。
其他注意事项
FSM编码
Binary(二进制编码)、gray-code(格雷码)编码使用最少的触发器,较多 的组合逻辑,而 one-hot(独热码)编码反之。one-hot 编码的最大优势在于状 态比较时仅仅需要比较一个 bit,一定程度上从而简化了比较逻辑,减少了毛 刺产生的概率。由于 CPLD 更多地提供组合逻辑资源,而 FPGA 更多地提供触 发器资源,所以 CPLD 多使用 gray-code,而 FPGA 多使用 one-hot 编码。另一 方面,对于小型设计使用 gray-code 和 binary 编码更有效,而大型状态机使用 one-hot 更高效。
FSM 输出
如果使用 2 段式 FSM 描述 Mealy 状态机,输出逻辑可以用”?语句”描述,或 者使用 case 语句判断转移条件与输入信号即可。如果输出条件比较复杂,而且 多个状态共用某些输出,则建议使用 task/endtask 将输出封装起来,达到模块 复用的目的。
FSM 的默认状态
完整的状态机应该包含一个默认( defauIt)状态,当转移条件不满足或者状态发生突变时,要能保证逻辑不会陷入”死循环”这是对状态机健壮性的一个重要要求,也就是常说的要具备”自恢复”功能。对应于编码上就是对case 和if…else 语句要特别注意,尽量使用完备的条件判断语句。Verilog 中,使用case 语句的时候要用defauIt建立默认状态。其实我们可以将其中一个状态不编码,指定其为default 默认状态,则任何与所列状态机不匹配的状态都会转到default 状态,从而增强了FSM 的健壮性,另外也可以添加一个额外的default 状态,电路一旦运行到这个状态,就会自动跳转到IDLE 状态,从新启动状态机,这样做也能增强状态机的健壮性。
Testbench的编写,todo